for deep learning, improves linear classifiers
requires activation functions to become non-linear
new hyperparams
- num layers
- what the layer is?
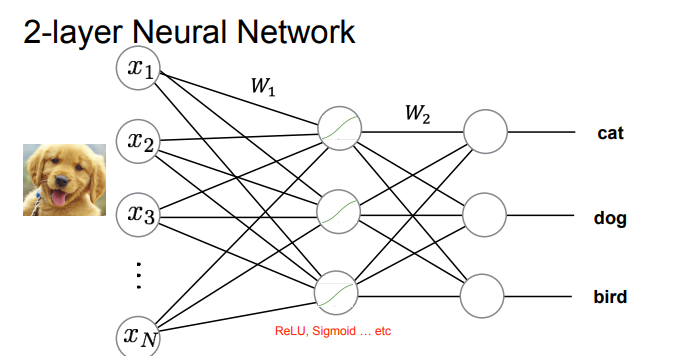
activation functions
- step functions - binary output - hard to optimize
- sigmoid - smooth, but vanishing gradients (flat regions = slow learning)
- ReLU - keeps gradients constant for positive inputs, fixes flat regions
architecture
- fully connected layers: every input connects to every output
- param efficiency: large inputs require billions of params…