Linear transformation method that maximizes class separation - good for classification because it maximizes both variance and class discrimination - good for feature reduction in ML
LDA is a linear transformation method like principal component analysis (pca), but with a different goal.
The main difference is that LDA takes information from the labels of the examples to maximize the separation of the different classes in the transformed space.
Therefore, LDA is not totally unsupervised since it requires labels. PCA is fully unsupervised.
- cares about maximizing both variance and class discrimination
In summary:
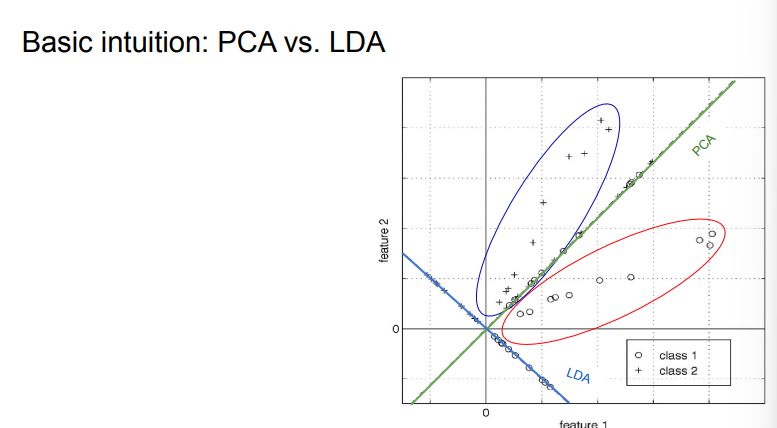
- PCA perserves maximum variance in the projected space.
- LDA preserves discrimination between classes in the project space. We want to
- maximize scatter between classes (keep pts of same class close together)
- minimize scatter intra class (push diff classes as far apart as possible) So, LDA is good for classification tasks, where we want reduced dimensions to still keep different categories distinct.
LDA optimizes the ratio
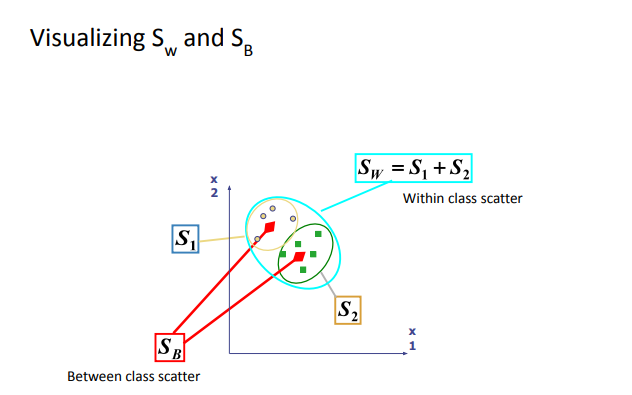
- between-class () measures how far apart class means are
- within-class () measures how tightly clustered each class is
ex. for two classes
this ratio should be as large as possible, meaning classes are far apart (large num) and individually compact (small denom)
the optimal projection W is given by eigenvectors+values of
for C classes
- becomes sum of each class’s covariance matrix
- becomes sum of squared diffs between all class means Solution: take top e-vecs to project data to a lower-dim space