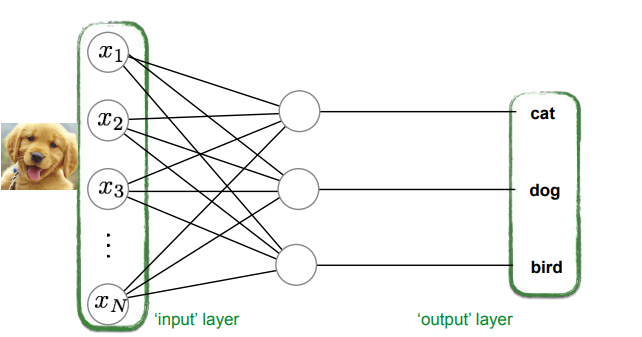
is a set of perceptrons that produces one score for every category
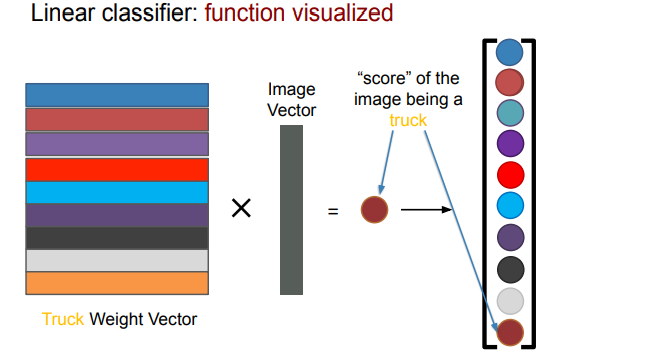
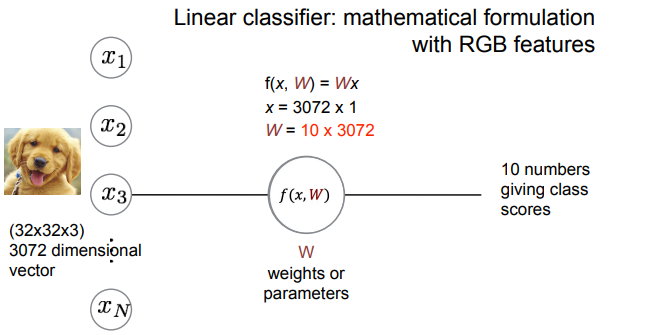
- add on bias vector
- argmax gives classification
- interpret output as probability with softmax
- interpret weights as templates:
- reshape the output vector back into shape of an image
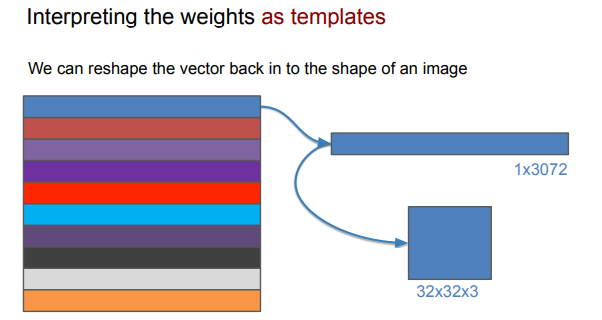
- reshape the output vector back into shape of an image
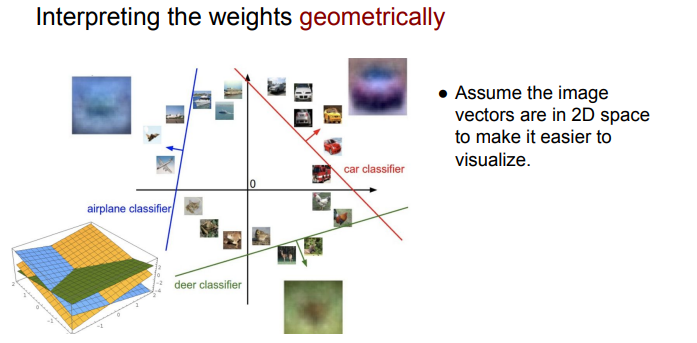
- interpret weighs geometrically
training
- learn how to pick weights
- find W such that
- where y is true label, y_hat is predicted label
- define loss function
- when classifier is correct, loss should be low
- when classifier makes mistakes, loss should be high
summary
Key
- input layer (vector)
- weight matrix - params that transform inputs to outputs
- output layer - transformed predictions Learning
- softmax activation - convert scores to probs
- loss function (cross-entropy) - measure prediction error
- Loss = -log(prob of correct class)
- gradient descent and backpropagation
- optimize weights using chain rule linear models are the foundation for neural networks
limitations
- assume linear separability (data can be divided by a hyperplane)
- we need nonlinearity
- feature transformation: learn mapping that makes data linearly separable
- neural networks - nonlinear activations